Loading Data
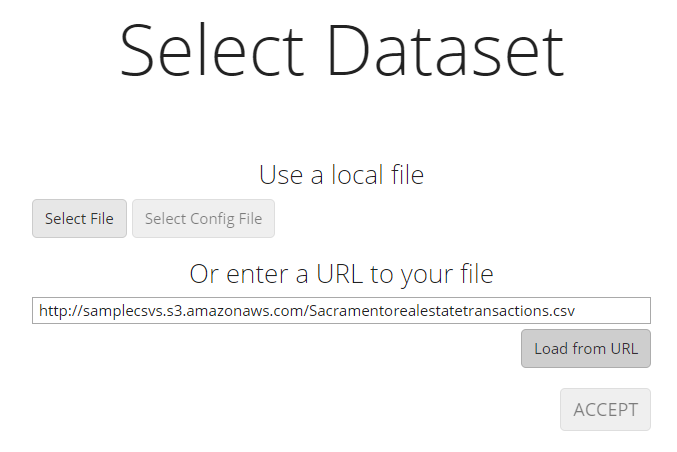
When visiting Visualizer, the first thing which can be seen is the starting page that prompts the user to select a file.
The file can be loaded either from the local machine, or from an arbitrary URL, as long as it is of a file type which is supported by Visualizer. Additionally to the data source file, a configuration file can be added that automatically configures the dataset in a certain way. How to create a configuration file will be covered in the chapter about the dataset table.
Supported Data Sources
As data sources, Visualizer currently supports only CSV and JSON. The JSON has to be additionally in a specific format, which allows Visualizer to load even bigger datasets. The JSON should be an array of objects, with each object representing one column in the dataset. Each object should have two attributes:
- fieldname [string] - The name of the column
- data [array] - The entries in the column
Therefore, a valid JSON which can be loaded into Visualizer would look as follows:
[{
"fieldname" : "fruits",
"data" : ["apple", "banana", "orange"]
},
{
"fieldname" : "quantity",
"data" : ["10", "15", "20"]
},
{
"fieldname" : "color",
"data" : ["red", "yellow", "orange"]
}]
As a sample file for this tutorial, the real estate transactions will be used of the Sacramento area.
http://samplecsvs.s3.amazonaws.com/Sacramentorealestatetransactions.csvThe file will be loaded directly over the URL. This makes using the configuration and bookmark links much easier.